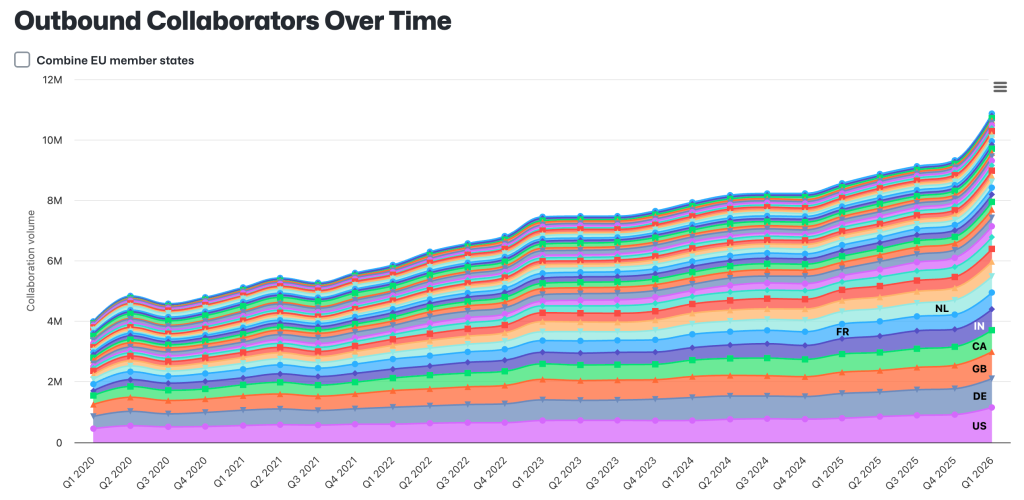
SWE-bench Verified
% resolvedShare of real GitHub issues resolved end-to-end.
↑ higher is betterSWE-bench
- #01OpenHands + GPT-571.8%
- #02Moatless Tools + Claude 4 Sonnet70.8%
DevTools vendors are betting on AI agents, but they're building the wrong abstraction layers—and the cost of fixing it later will be steep.

Cloudflare’s UK Cyber Pledge signature is the sovereignty moat no one saw coming

JetBrains’ Caveman Test Backfires: Token Savings Miss by 85%, Exposing AI Agent Hype

CircleCI Bets on LSP to Turn Claude Code into the Default AI Pair Programmer

Mistral's Leanstral 1.5 bets small models can reason—and prove it

Builds frontier large language models including GPT and Codex that power the majority of AI coding tools via API, plus first-party products like ChatGPT and Codex CLI.

Creates Claude — the frontier LLM family that powers Claude Code, the terminal-based coding agent that became the breakout developer tool of 2025.

Builder of Cursor, the AI-native code editor that has become the professional developer's tool of choice for agent-assisted coding with multi-file edits, repo-wide context, and model-agnostic backend.

Creator of Devin, the first autonomous AI software engineer that can plan, write, test, and deploy complete software projects from natural-language specifications.
European foundation model lab producing the Mistral and Codestral model families with competitive coding performance and a strong focus on sovereignty and on-premise deployment for EU enterprises.

Vibe-coding platform enabling developers and non-technical users to create and deploy web applications from natural-language prompts, reaching $200M ARR in under two years.

Provides durable execution infrastructure that ensures AI agent workflows are resilient to failures, with automatic retries, state persistence, and human-in-the-loop orchestration for production-grade agents.

AI-powered browser-based software creation platform that combines an online IDE, AI coding agent, and deployment infrastructure used by employees at 85% of Fortune 500 companies.

Powers the AI Cloud platform combining Next.js, v0 AI development agent, and edge deployment infrastructure that turns natural-language prompts into production applications.

Provides the dominant open-source framework for building AI agents plus LangSmith, a commercial platform for tracing, evaluating, and monitoring LLM-powered applications in production.

Serverless cloud for AI and data workloads that lets engineers run Python at scale on pooled CPUs and GPUs with sub-second container starts and per-second billing.

Open-source observability platform providing dashboards, metrics, logs, and traces, recognized as a Leader in the 2025 Gartner Magic Quadrant for Observability Platforms.

End-to-end platform for LLM evaluations, prompt engineering, and production observability, used by Notion, Replit, Vercel, Cloudflare, Ramp and Stripe to ship AI features with confidence.

AI-powered code review platform that provides automated, context-aware pull-request reviews across GitHub, GitLab, and Bitbucket with multi-layered analysis and line-by-line suggestions.

Agentic AI development platform with five specialized agents for test generation, code review, coverage analysis, deep research, and workflow automation, formerly known as CodiumAI.

Open-source secure cloud sandboxes that give every AI agent its own isolated Linux computer to run code, browse files, and use real-world tools — adopted by 88% of the Fortune 100.

Releases the open-weight Llama model family including Code Llama, which enables on-premise and self-hosted AI coding tools for enterprises with data-residency requirements.

AI lab building foundation models purpose-trained for software engineering, with a model architecture designed specifically for code generation and understanding rather than general-purpose conversation.

Modern issue-tracking and project-management tool purpose-built for software teams, with AI features for automated triage, summarization, and workflow orchestration across the development lifecycle.

Enterprise-focused AI coding assistant providing dependency mapping, architectural analysis, and context-aware code generation tuned for large-scale, complex codebases.

AI-native application security platform that finds and auto-fixes vulnerabilities in code, open-source dependencies, containers, and infrastructure as code, with DeepCode AI powering its analysis engine.

Creator of Bolt.new, a browser-based AI development platform that lets non-technical users spin up full-stack web apps with natural language, integrated Supabase storage, and instant Netlify deployment.

Complete DevSecOps platform with integrated CI/CD, source control, and emerging AI capabilities including code suggestions, vulnerability explanation, and merge-request summarization.

Cloud-scale observability platform that added LLM Observability for end-to-end tracing across AI agents with visibility into inputs, outputs, latency, token usage, and errors.

Developer-first application monitoring platform that uses AI to achieve 95% root-cause accuracy on errors and is expanding into automated code remediation and AI code review.

Provides Cody, an AI coding assistant that uses repository-wide code search and context to answer questions, generate code, and explain codebases with deep understanding of the full code graph.

Container platform that launched Docker Sandboxes for safe AI agent execution and Docker Hardened Images to provide trusted base environments for AI-generated code.

Web deployment platform pioneering Agent Experience (AX) — infrastructure built for AI agents to deploy and manage projects through MCP servers, Agent Runners, and natural-language-driven provisioning.
Cloud-based CI/CD platform adapting to the AI era with AI-powered pipeline debugging, test-splitting optimization, and integrations with AI coding agents for automated build-and-test loops.

ML and LLM observability platform with OpenTelemetry-based tracing, real-time evaluations, and agent observability for multi-step AI agent traces in production.
Global cloud platform providing Workers AI for serverless AI inference, AI Gateway for monitoring and caching LLM calls, and edge infrastructure that serves as the deployment backbone for AI-generated applications.

Infrastructure-as-code platform that launched Pulumi Neo, a purpose-built AI agent for automating cloud infrastructure tasks including provisioning, security, and compliance at enterprise scale.

AI-native terminal that has evolved into the Agentic Development Environment (Warp 2.0), a platform for coding with multiple parallel AI agents from the command line.

Enterprise AI coding assistant purpose-built for organizations with complex codebases, mixed tech stacks, and strict security requirements, supporting on-premise and air-gapped deployment.

Observability platform built for high-cardinality data exploration, using AI-powered querying and anomaly detection to help engineering teams understand complex distributed systems.

Open-source AI code assistant that works as an IDE extension across VS Code and JetBrains, allowing developers to choose any model provider and customize their AI coding experience.

AWS's AI coding assistant providing code generation, security scanning, and infrastructure suggestions deeply integrated with the AWS ecosystem and supporting agentic code transformation tasks.
Maker of professional IDEs including IntelliJ, PyCharm, and GoLand used by millions of developers, now with JetBrains AI Assistant providing context-aware code completion and generation across all its tools.
Edit-format correctness across six programming languages.
Head-to-head: models write bots that compete in programming-game arenas.
Published price, 3:1 input:output blend — lower is cheaper.
JetBrains research finds coding benchmarks overstate model gains by measuring narrow tasks, proposes better evaluation methods at ICML workshop.
Two cross-listed frontier labs distort the totals: OpenAI's $110B at $840B and Anthropic's $30B Series G at $380B drove a $141.8B 2026 total in eight deals. Strip them and the pure-tooling tier still ran hot — Anysphere's $2.3B Series D at $29.3B, Mistral's $2B, Cognition's $400M — as the median round tripled from $50M in 2023 to $400M in 2026.
Capital moved decisively late: of 32 rounds since 2025, ten were growth-stage and seven Series C, against just two seeds and two Series As. The 2023–24 seed-and-A base (16 of 43 rounds) has thinned to a trickle. M&A stays active at the top — IBM's $6.4B HashiCorp buy, then ClickHouse absorbing Langfuse in January 2026.
Accel leads the field with 14 rounds and is still pricing them (Anysphere, November 2025); Lightspeed (nine) took Anthropic and Grafana, Andreessen Horowitz (nine) led Temporal. The new entrants are strategic — ASML led Mistral's $2B, Nvidia joined OpenAI, ClickHouse bought Langfuse. Sequoia, a ten-time lead, hasn't led since February 2024.